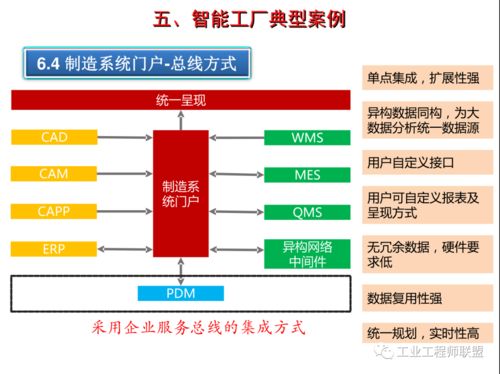
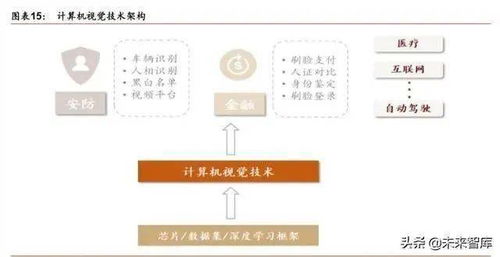
軟件測試與測試開發新利器 利用ChatGPT高效批量生成測試數據
在軟件測試和測試開發領域,測試數據的準備一直是一個耗時且繁瑣的環節。高質量、多樣化且覆蓋各種邊界情況的測試數據對于保證軟件質量至關重要。人工智能的快速發展為解決這一痛點提供了新思路,特別是像ChatGPT這樣的大型語言模型,正在成為測試工程師手中的強大工具,能夠高效、智能地批量生成測試數據,從而顯著提升測試效率和測試覆蓋度。
一、傳統測試數據生成的挑戰
傳統上,測試數據的生成主要依賴手工創建、使用腳本工具或從生產環境脫敏后導入。這些方法往往存在以下問題:
- 效率低下:手工創建數據耗時耗力,難以滿足快速迭代的需求。
- 覆蓋不全:難以系統性地生成覆蓋所有等價類、邊界值和異常場景的數據。
- 真實性不足:腳本生成的數據可能過于規整,缺乏真實世界數據的復雜性和關聯性。
- 維護成本高:隨著業務規則變化,測試數據需要頻繁更新,維護負擔重。
二、ChatGPT在測試數據生成中的優勢
以ChatGPT為代表的大語言模型,憑借其強大的自然語言理解、上下文學習和內容生成能力,為測試數據生成帶來了革命性變化:
- 自然語言驅動,易于使用:測試工程師可以用簡單的自然語言描述數據需求(例如:“生成50條用戶注冊信息,包含無效郵箱、短密碼、特殊字符用戶名等異常情況”),ChatGPT便能理解并生成符合要求的結構化數據(如JSON、CSV格式)。
- 智能生成多樣化數據:能夠根據要求,自動生成包含正常值、邊界值、無效值、特殊字符、多語言內容等在內的多樣化數據,輕松構造復雜的測試場景。
- 理解業務邏輯與關聯性:可以基于對業務場景的描述,生成具有內在邏輯關聯的數據集。例如,生成一個完整的電商訂單流程數據,涵蓋用戶、商品、訂單、支付等多個相關聯的實體。
- 快速迭代與定制:當測試需求變化時,只需調整提示詞(Prompt),即可快速生成新的數據集,適應敏捷開發節奏。
三、實踐應用場景與方法
在測試開發工作中,可以系統性地集成ChatGPT的API,構建自動化的測試數據生成流水線。
基礎應用示例:
- 生成基礎實體數據:如用戶信息、產品目錄、地理位置等。
- 構造邊界與異常數據:針對輸入框,生成超長字符串、SQL注入片段、XSS攻擊腳本等安全測試數據。
- 模擬復雜業務流數據:生成從登錄、瀏覽、加購、下單到售后全鏈路的連貫測試數據。
進階開發集成:
1. 封裝為測試數據服務:將調用ChatGPT API的功能封裝成獨立的服務或庫,供不同的測試腳本或測試平臺調用。
2. 結合測試框架:在PyTest、JUnit等測試框架中,通過Fixture或Data Provider機制,動態獲取由ChatGPT生成的測試數據。
3. 實現數據模板與變量化:設計可復用的提示詞模板,通過變量替換生成不同規模、不同類型的數據集。
4. 確保數據隱私與合規:對于涉及個人敏感信息的測試,可明確要求模型生成完全虛構、不涉及任何真實個人的合成數據。
四、人工智能基礎軟件開發的支撐作用
這一應用的順利實現,離不開成熟的人工智能基礎軟件的支持:
- 模型API與SDK:OpenAI等平臺提供的穩定、高效的API接口和軟件開發工具包,是集成能力的基礎。
- 提示工程(Prompt Engineering):如何設計精準、清晰的提示詞以引導模型生成高質量、格式正確的測試數據,是發揮其效能的關鍵技能,也屬于AI基礎軟件應用層的重要知識。
- 數據處理與格式化:生成的數據通常需要進一步清洗、格式化(轉為JSON、SQL插入語句等)才能被測試系統直接使用,這需要相應的數據處理腳本或工具。
五、注意事項與未來展望
當前注意事項:
- 生成結果的驗證:AI生成的數據并非100%準確,仍需進行抽樣驗證,確保其符合業務規則和測試意圖。
- 成本與效率平衡:頻繁調用商業API會產生成本,需根據數據規模和復雜度評估性價比。
- 提示詞技巧:需要不斷積累和優化提示詞,以得到更精準的輸出。
未來展望:
隨著多模態AI模型的發展,未來不僅可以生成文本和數值型測試數據,還能生成用于UI/接口測試的圖片、音頻甚至視頻數據。測試數據生成將更加智能化、自動化,并與測試用例設計、測試執行更深度地融合,成為“AI+測試”生態的核心環節之一。
###
將ChatGPT等AI能力引入測試數據生成環節,是測試開發工程師提升工作效率、擴展測試覆蓋深度的有效實踐。它并非要完全取代傳統方法,而是作為一種強大的輔助和增強工具。掌握這項技能,意味著測試人員能將更多精力投入到更具創造性的測試設計、缺陷分析和質量保障策略制定中去,從而在人工智能時代更好地保障基礎軟件與應用軟件的質量與可靠性。
如若轉載,請注明出處:http://m.5xbg.cn/product/69.html
更新時間:2026-04-08 04:34:08